Method
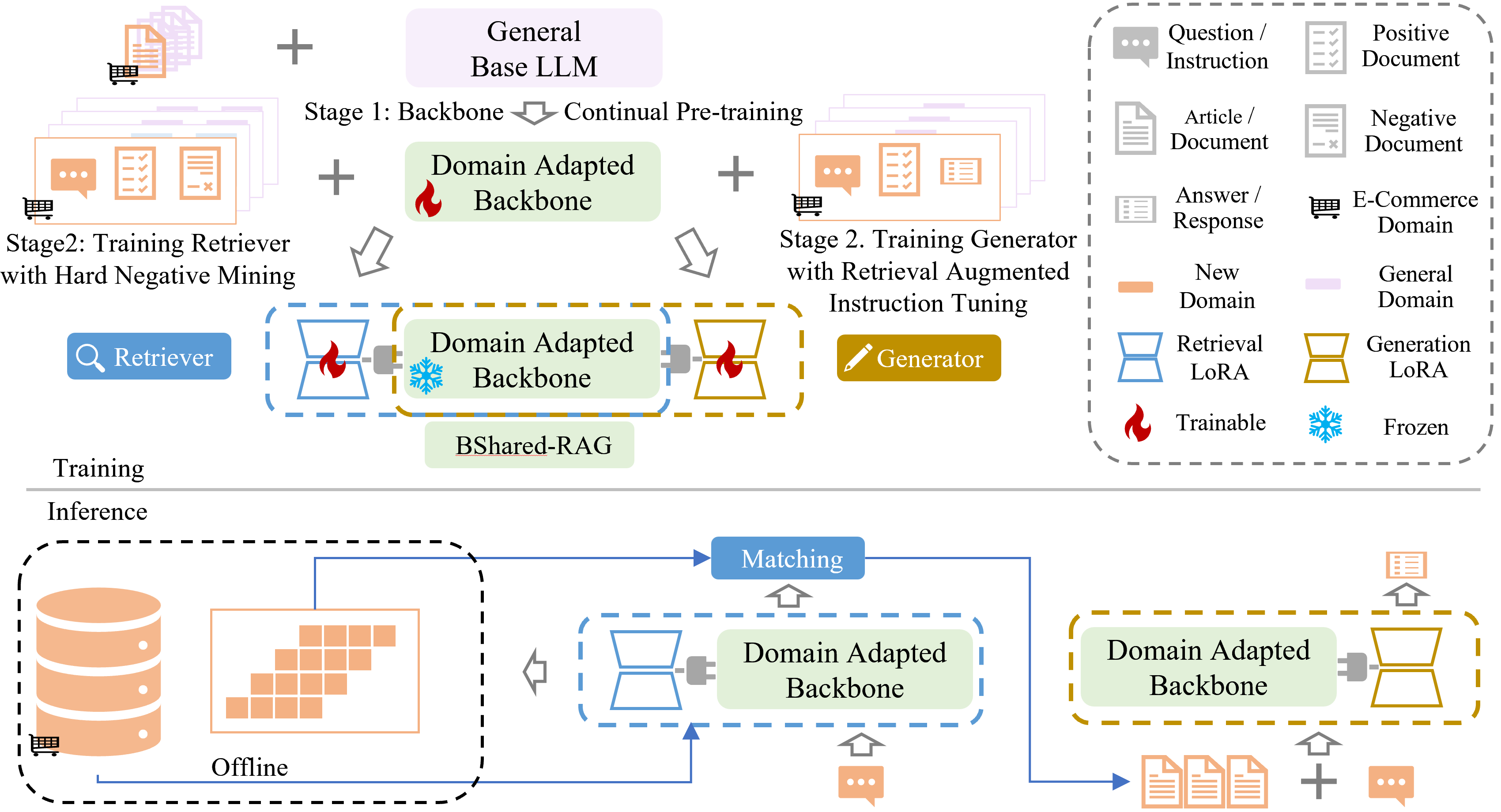
Figure 1. The architecture of the proposed BSharedRAG framework. The shared domain-specific backbone is pre-trained on a domain-specific corpus and then fine-tuned on the target dataset. The LoRA modules are trained based on the shared backbone to minimize retrieval and generation losses respectively.
WorhBuying Dataset
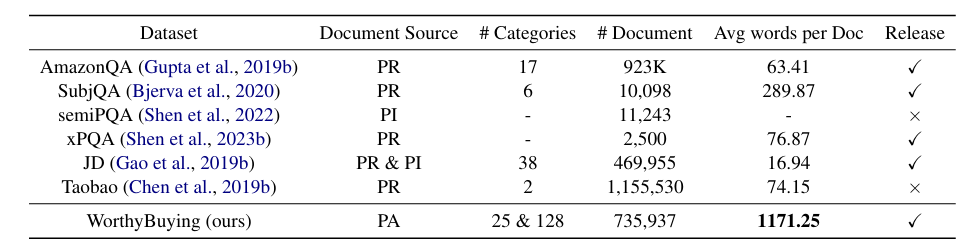
Table 1. Comparison of Product Question Answering (PQA) datasets. The average document word count metric is derived from a sample of documents within each dataset. The document types are classified into Product Reviews (PR), Product Information (PI), and Product Analysis from professional users (PA) .
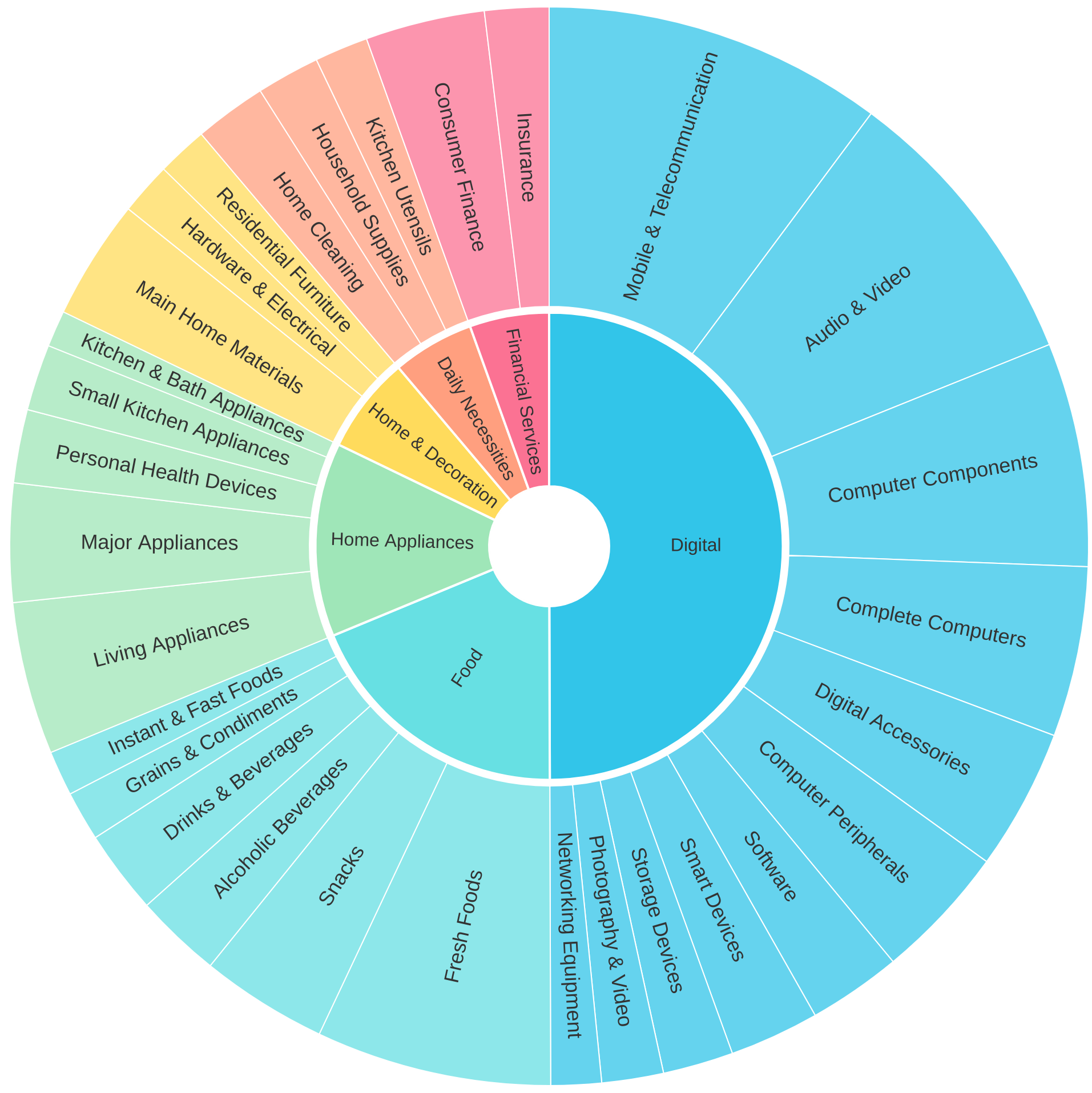
Figure 2. Partial categories of WorthBuying dataset
Experiment
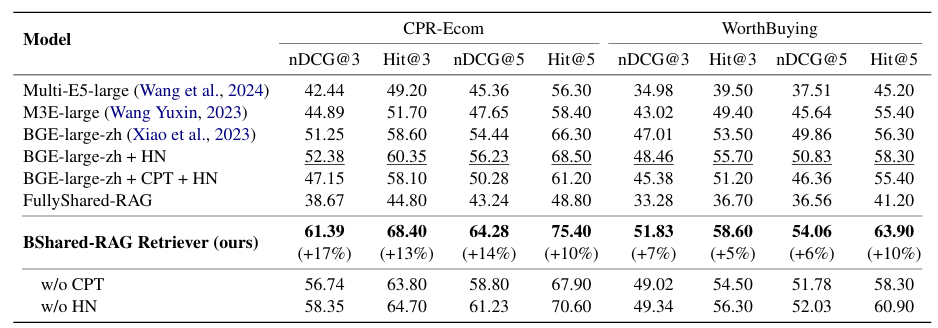
Table 2. Comparing retrievers of different RAG frameworks. CPT denotes continual pre-training and HN denotes using hard negative samples. Our BShared-RAG Retriever outperforms all baselines by a large margin. CPT fails to help the BGE adapt to the e-commerce domain and even hurts the performance. FullShared-RAG performs the worst, showing that sharing all parameters between retrieval and generation leads to severe performance degradation.
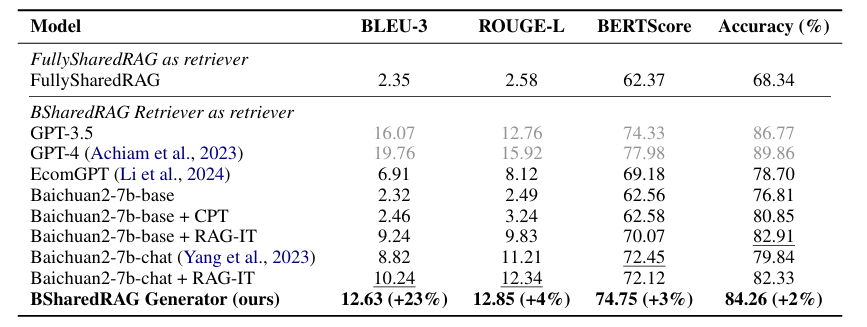
Table 3. Evaluation of generation results based on different retrievers on the WorthBuying-PQA test set. RAG-IT denotes retrieval augmented instruction tuning. The FullySharedRAG method performs worse because the generation objective may conflict with the retrieval objective. Compared with Baichuan2-7b series of baselines, our model achieves the best performance, demonstrating both CPT and RAG-IT contribute to the final performance.
Example
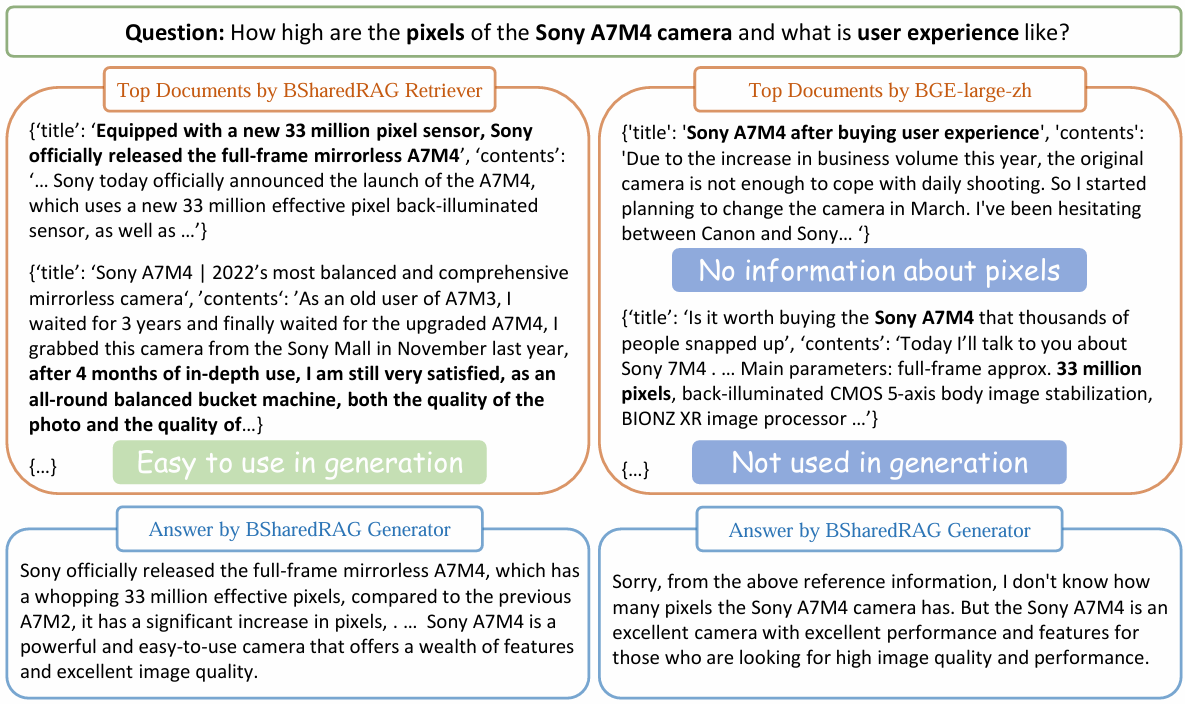
Figure 3. A representative example to compare our BSharedRAG with a separate RAG. For the given question, our BSharedRAG Retriever favors the documents, in which some sentences are easy to be generated from the prompt of question. In contrast, the BERT-like BGE-large-zh model tends to retrieve some documents, in which some sentences match the question well. However, such document may be less suitable for generating answers due to some issues, for example, important information missing or not easy to be used by generators.